



Яндекс запустил новый поисковый алгоритм под названием «Палех», который позволяет точнее понимать, о чем его спрашивают пользователи. Благодаря «Палеху» поиск лучше находит веб-страницы, которые соответствуют запросам не только по ключевым словам, но и по смыслу.
1. А можно конкретнее?
Смотрите, каждый день поиск Яндекса отвечает примерно на 280 млн запросов. Некоторые, такие как [вконтакте], люди вводят в поисковую строку практически каждую секунду. Но есть уникальные запросы — их задают один раз, и они, возможно, больше никогда не повторятся. Уникальных и просто редких запросов — около 100 млн в день.
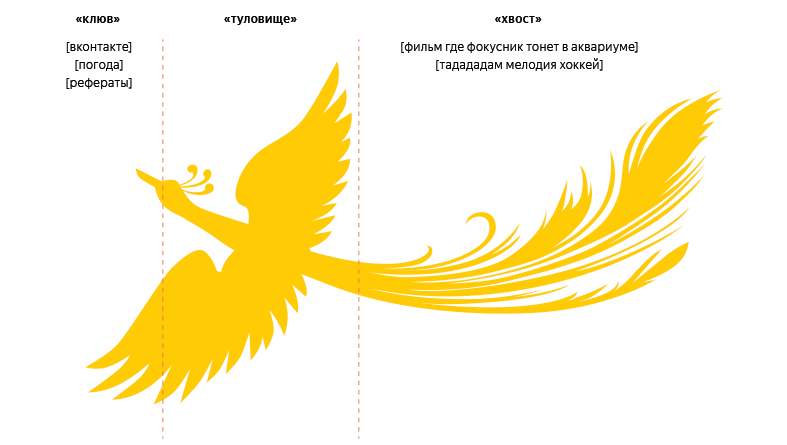
Как пишут в блоге Яндекса, график частотного распределения запросов часто представляют в виде птицы, у которой есть клюв, туловище и длинный хвост. Список самых распространенных запросов — это «клюв», запросы средней частотности образуют «туловище», а низкочастотные запросы складываются в «хвост».
Новый алгоритм позволяет поиску Яндекса лучше отвечать на сложные запросы из этого «длинного хвоста».
2. А почему новый алгоритм назвали «Палех»?
Такой хвост есть у сказочной Жар-птицы, которая часто появляется на палехской миниатюре, отсюда и название.
3. Примеры приведете?
Среди запросов из «длинного хвоста» можно выделить несколько групп. Например, запросы от детей, которые обращаются к поиску как к живому собеседнику: [дорогой яндекс посоветуй пожалуйста новые интересные игры про фей для плантика]. Еще одна группа — запросы от людей, которые хотят узнать название фильма или книги по эпизоду: [фильм про человека который выращивал картошку на другой планете] («Марсианин») или [фильм где физики рассказывали даме про дейтерий] («Девять дней одного года»).
4. Почему так сложно найти ответы на такие запросы?
Запросы из «клюва» задают многократно, поэтому для них есть масса разнообразной пользовательской статистики. Чем больше знаний о запросах, страницах и действиях пользователей накопил поиск, тем лучше он находит релевантные результаты. В случае с редкими запросами статистики нет, и Яндексу гораздо труднее понять, какие сайты хорошо подходят для ответа. Как поясняют в компании, задача осложняется тем, что далеко не всегда на релевантной страничке встречаются слова из запроса: один и тот же смысл в запросе и на странице может быть выражен по-разному.
5. Что в основе нового алгоритма Яндекса?
К решению задачи привлекли нейронные сети — один из методов машинного обучения. Их, например, можно обучить распознавать на изображениях те или иные объекты — цветы, собак и т. д. Происходит это так: показывают много картинок, где есть нужные объекты (положительные примеры) и где их нет (отрицательные примеры). В результате нейросеть получает способность верно определять нужные объекты на изображениях.
В случае с поиском речь идет о текстах — это тексты поисковых запросов и заголовков веб-страниц. Однако схема такая же — на положительных и отрицательных примерах. Каждый пример — это пара «запрос-заголовок». Подобрать примеры можно с помощью накопленной поиском статистики. Обучаясь на поведении пользователей, нейросеть начинает «понимать» смысловое соответствие между запросом и заголовками страниц.
6. И что дальше?
Семантический вектор применяется не только в поиске Яндекса, но и в других сервисах — например, в Картинках.
Вообще, технология обладает огромным потенциалом: переводить в такие векторы можно не только заголовки, но и полные тексты документов — это позволит еще точнее сопоставлять запросы и веб-страницы. В виде семантического вектора можно представить и профиль пользователя в интернете: есть его интересы, предыдущие поисковые запросы, переходы по ссылкам.







